Introduction - Why talk about RAG in 2026?
As we keep surfing the AI wave, one of the recurring topics of discussion is cost.
If you’re a frontier lab like OpenAI or Google, you scale up by building data centers and buying put options on energy.
If you’re a major company like Uber or Snowflake, you start by building “tokenmaxxing dashboards”, until you inevitably need to place guardrails on how much your employees spend; Uber is capping its engineers to $1,500 per month.
Like anything, you get it working, build intuition around it, then optimize. Tony Fadell has a great framework for this:
- Build the product
- Fix the product
- Fix the business model
Similarly, with AI usage, we’re in the era of “spending doesn’t matter if it’s providing value”. While this is true, spending has to be sustainable.
I personally believe there are two levers we can pull for the low hanging fruit:
- Fine-tuning
- RAG
There’s a lot here on propriteray data sets, learning very narrow domains, and being cost-efficient in those domains. Will discuss my ideas in more depth in the future.
Introducing Contextual Retrieval Review
The very first blog post Anthropic published on its dedicated engineering blog was in 09/19/2024 titled Introducing Contextual Retrieval.
RAG Background
RAG (Retrieval Augmented Generation) is well known and studied:
- Retrieve relevant info to prompt - Projecting an embedding of the user’s prompt to a pre-processed vector database; vector search.
- Augment the original prompt - Usually by selectively appending to or modifying the context.
- Generate the result - Run inference on the augmented prompt with additional context.
The goal of Anthropic’s publication is to surface Contextual Embeddings, which reduce the number of failed retrievals by 49%, and later by 67% when combined with re-ranking.
I won’t provide a primer on step (1), but there are some nuances involved in deciding how to chunk a data corpus and what kind of encoder to use to generate the embeddings, before hydrating the Vector DB.
Naive Solutions
When not to use RAG? If your knowledge base is less than 500 pages (200K tokens), just append all of it into context.
Prompt caching is another simple approach that caches the results of certain prefixes or API calls.
For both of these, there’s a lot to take into consideration. Model reliability and updates, cost of caching, the tradeoff of potentially positioning your context and much more.
BM25 and TF-IDF for RAG - Terminology Index
Anthropic suggests an approach that supplements the single-path semantic embedding retrieval in RAG via BM25.
Some terminology first. BM25 Best Matching 25 builds on TF-IDF (Term Frequency-Inverse Document Frequency), to look for specific text strings - such as “HTTP ERROR 402” - to make sure we don’t generalize to just “HTTP ERROR”.
I want to reiterate the steps from the blog post, but at a high level, the idea is:
- Find semantic similarity via embeddings
- Find BM25 matches via TF-IDF encodings
- Group, remove duplicates, and do RAG

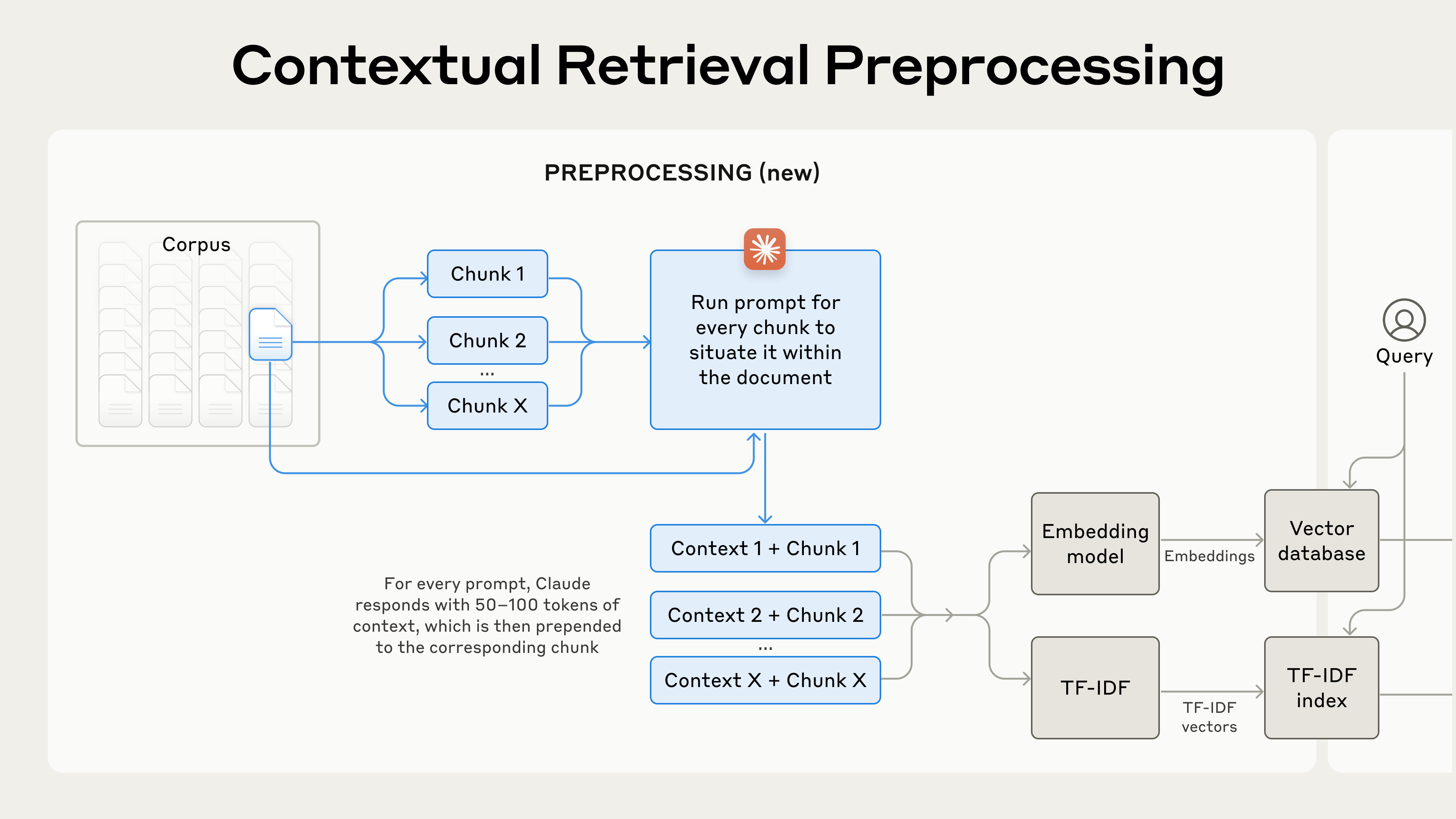
Introducing Contextual Retrieval - Context Prefix
The overarching premise of the idea behind contextual retrieval is:
“Contextual Retrieval solves this problem by prepending chunk-specific explanatory context to each chunk before embedding (“Contextual Embeddings”) and creating the BM25 index (“Contextual BM25”).”
The idea is simple yet powerful. Use an LLM to generate a small amount of contextual text (50-100 tokens) for every chunk, before embedding it or creating the BM25 index.
Prompt Caching - Reduce costs
“Assuming 800 token chunks, 8k token documents, 50 token context instructions, and 100 tokens of context per chunk, the one-time cost to generate contextualized chunks is $1.02 per million document tokens.”
The takeaway is that because the contextual prefix is generated using the same model, generating the contextual prefix for every chunk is quite cheap.
The results were good, but the more important parts are the learnings and considerations:
- Chunk boundaries: Chunk size, boundary, and overlap are critical to performance. These are the “hyperparameters” of embedding engineering.
- Embedding model: LLMs are still black boxes, and how contextual retrieval performs on different ones still requires per model eval.
- Custom contextualizer prompts: The prompt engineering to generate the chunk prefixes requires lots of tuning and evals.
- Number of chunks: When appending the top K chunks to the prompt, choosing K correctly is an art more than a science.
Re-ranking
I recently read the 2016 Youtube DNN paper. Though it’s been a decade, it’s an awesome primer on how large scale recommendation systems work. I genuinely believe it is still as relevant today as it was 10 years ago.
If you look closely at Figure 2, the last step is a ranker. After the two-tower ANN search, and typical heavyweight/lightweight models, we usually end with ranking before showing the result.
My intuition is that these systems will need to be custom built, evaluated, and tuned per data corpus and domain. There is no silver bullet:
“There is an inherent trade-off between reranking more chunks for better performance vs. reranking fewer for lower latency and cost. We recommend experimenting with different settings on your specific use case to find the right balance.”
Footnote
I highly recomment this 2016 from Google if you need a primer on recommendation systems: Deep Neural Networks for YouTube Recommendations (2016).