When I first saw the title of OpenAI’s blog, I wasn’t too excited. Here it is: Building self-improving tax agents with Codex.
Tax agents don’t sound exciting. Everything is self-improving. I got it. But this short post is a masterclass in practical, hands-on learnings on the latest tools, workflows, and approach to how to do evals for real-world use cases. It’s not just technical; it builds intuition by relying on real-world experience.
This is the post I wish I had when I first started my job at Waymo.
Finding the Right Hill to Climb
Any ML/AI practitioner would appreciate this strong open:
“Real-world systems behave differently in production than they do in a lab, breaking in ways that are hard to anticipate before deployment.”"
To get things started: the problem wasn’t “Can we use AI for taxes?”, it was:
“They pointed us to tax preparation as a significant bottleneck during the busiest stretch of tax season.”
Without getting into the weeds, the core problem involves uploading a bunch of documents -> accurately parsing and extracting data from PDFs, and measuring accuracy by looking at data completion % along with returns flagged for manual review.
Like any real-world eval problem, there are three key pillars to the feedback loop:
- Feedback: To make sure you’re solving the right problem(s), in the right order, in a domain you might not be an expert in, you need to work as closely as possible with the end customer. This drives the data you’ll be looking at.
- Eval: Production traces, hold-out sets, golden test set corpuses, and much more. This requires trial-and-error along with experience. Feedback will drive what you should evaluate.
- Self-improvement: You need the model to actually improve. This might be model routing, prompt tuning, post-training (e.g. fine-tuning), setting thresholds based on the evals, etc. This is what actually drives the results.
I really like this quote at the end of the problem statement:
“We did not have the signal to identify the right hill to climb.”
That gap is what drove their methodology, one applicable to any field.
This is the playbook for Forward Deployed Engineers in the era of AI:
- Stay close to practitioners
- Build the product so production creates evidence
- Create a Codex-driven improvement loop
From Production Traces to Evals
The post goes into a concrete example on managing rental properties where the financial details may be spread across multiple documents: spreadsheets, PDFs, hand-written notes, etc…
The interesting part about capturing your precision and recall is that negative samples are not always objective, they may be practitioner preferences.
This is a very simple but very real framing. It’s why we’ll need fine-tuning per organization. Maybe, one day, per team? Per person? People laughed at the idea of “personal computers” too. I’ll share more of my thoughts here in another post.
OpenAI’s note on turning product traces into evals is split into three:
- Capture the difference between the filed return (by the human) and Tax AI’s output. This is great, the final return is the best sample we can get for our ground truth corpus.
- Group related failures to separate recurring errors from workflow noise. This helps with understanding the data, but also avoids overtraining/overfocusing on a specific vertical of failures.
- Turn repeated patterns into eval targets after review and measurement. Once you’ve found the hill, and you have the tools, and you have the baseline skills, climbing is quite fun.
As I finished writing the note above, and moved on to the next sentence, I saw: “Corrections become hill candidates.” :) OpenAI provided a really cool graphic that I’ll simply link to here.
{kind=link}
The next step is where most of the engineering work and time lies:
- Investigate the pipeline: packages, schemas, code paths, bugs, traces, logs, deployment environments, offline/online skew, etc.
- Implement the fixes: Update source selection, parsing, tax-engine, etc.
- Validate & propose: Re-run targeted evals, measure, run regression suites, consider deploying with an A/B test, shadow traffic, re-evaluate.
- Close the loop: Automate as much (not everything) as possible to have new metrics, test sets, dashboards, and visibility into the deployed changes.
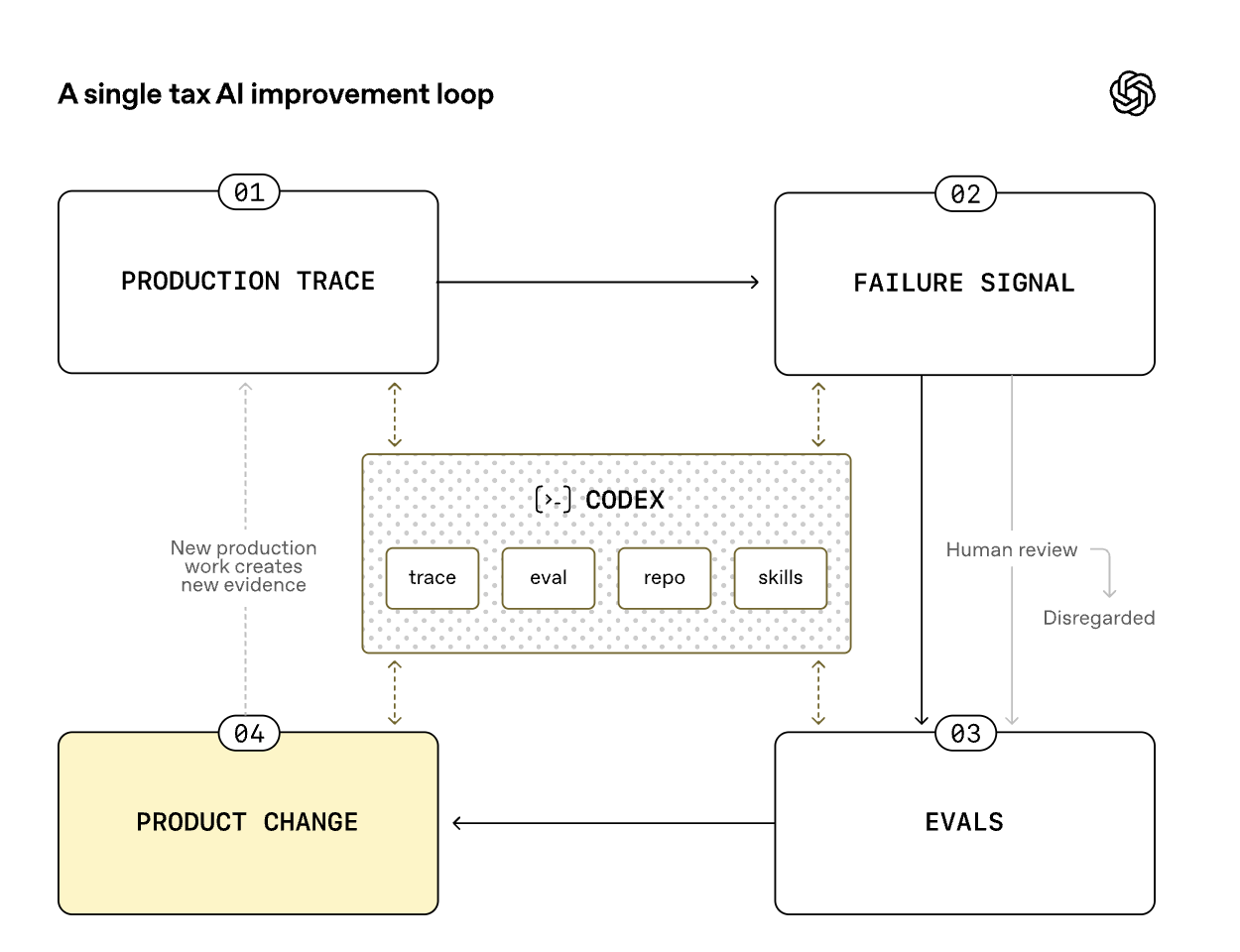
This next diagram I liked enough to drop inline:
{kind=link}
Why Forward Deployed Engineers Aren’t Going Anywhere
Like I said earlier on, this isn’t a Codex-specific blog. It is a blog to provide a view into what eval feedback looks like in the real world. The team says:
“The rental property example is emblematic of a broader reusable pattern: using production artifacts and traces to improve an agent’s capabilities.”
And if anyone ever asks why Forward Deployed Engineers aren’t going anywhere anytime soon, this is the answer:
That evidence does not become a Codex task automatically. A practitioner correction may reflect an extraction miss, a mapping issue, unsupported product behavior, tax judgment, or expected workflow noise. […] Engineers remain responsible for architecture, product decisions, and shipping.
The candidate workspace Codex operates in looks roughly like this:
/candidates/FIND-RENTAL-0042/
├── repo/ # branch: codex/fix-rental-0042
│ ├── AGENTS.md
│ ├── tasks/FIND-RENTAL-0042/
│ ├── app/tax-ai/rental-income/
│ ├── evals/
│ ├── skills/
│ └── docs/
└── scoped-tools/ # read-only production context
├── production-trace
├── source-artifacts
└── tax-engine-docs
The Numbers, and Fixing the Problem You Have
To close it out, some numbers are always great.
- The project took 6 weeks and reached 90% precision and recall.
- One senior accountant went from 180 hours to 15 hours on tax preparation last year.
I’ll also add one quote I came by recently from Bram Cohen, the creator of BitTorrent and someone I’ve had the pleasure of meeting a handful of times now. He’s very direct, pragmatic, fun, and practical. When it comes to evals in the real world, this hits:
“The trick is to fix the problem you have, rather than the problem you want.”
- Bram Cohen